Dieser Artikel ist 1995 in der iX erschienen, (c) Heise-Verlag. Er steht hier in einer Form zur Verfügung, die nur rudimentär formatiert aus dem ursprünglichen ASCII-Format gewonnen wurde. Verlinken des Artikels ist willkommen, Kopieren untersagt, Lesen all denjenigen nahe gelegt, die sich in Zeiten des allgegenwärtigen XMLs an die Wurzeln erinnern möchten... als die Revolution noch leise voranschritt :-)
Die Wiedergabe erfolgt hier mit Zustimmung der iX.
Die Standard Generalized Markup Language
Leise Revolution
Stefan Mintert
Im Bereich der Dokumentverarbeitung taucht immer öfter der Begriff der Standard Generalized Markup Language auf. Was verbirgt sich hinter dieser Bezeichnung, wo liegen die historischen Ursprünge und welche Möglichkeiten bietet SGML?
"Während der nächsten fünf Jahre werden Computerbenutzer die Gelegenheit bekommen, ihre schlechtesten Gewohnheiten abzulegen: Sie werden nicht länger mit jedem Computerprogramm arbeiten müssen, als ob es keinen Sinn hätte, Daten mit all ihren anderen Programmen zu teilen; sie werden nicht länger handeln müssen, als ob der Computer nur ein komplizierterer und etwas lebendigerer Ersatz für Papier wäre; nicht Tage mit Versuchen zubringen müssen, verschiedenartige Computer zur Kommunikation zu bringen, verschiedenartige Betriebssysteme kooperieren zu lassen; nicht Softwareprogramme besänftigen müssen, die scheinbar im Krieg miteinander stehen.
Zu einem sehr großen Teil ist die Standard Generalized Markup Language die Revolution, die diesen Fortschritt ermöglicht. [...]"
Geht diese Prophezeiung zu weit? Ist es zu gewagt, eine Aussage über die nächsten fünf Jahre der Computerentwicklung zu machen?
Tatsächlich stammt diese Vorhersage von Yuri Rubinsky von der Firma SoftQuad und leitet das Vorwort der SGML-Bibel, dem "SGML Handbook", ein. Charles Goldfarb, der geistige Vater und Mitentwickler von SGML, hat dieses Buch geschrieben. Das Vorwort dazu hat Rubinsky bereits im August 1990 verfaßt. Seine Revolution ist also längst im Gange. Bisher ist sie recht leise und von vielen unbemerkt verlaufen, wenn man von der Hypertext Markup Language (HTML) absieht. Und dieser SGML-Ableger, den der Erfolg des World-Wide-Web bekannt gemacht hat, wird meistens wie ein eigenständiges Textformat benutzt. Begriffe wie "DTD" oder "SGML-Parser" sind WWW-Clients in der Regel noch immer unbekannt.
Doch das ist die Gegenwart. Auch wenn man beim Thema SGML kaum um HTML herumkommt, reichen die historischen Wurzeln von SGML doch viel weiter zurück.
Anfänge in den sechziger Jahren
Die wesentliche Idee, nämlich das Konzept des "generic coding", ist bereits fast dreißig Jahre alt. William Tunnicliffe von der Graphic Communications Association (GCA) machte im September 1967 den Vorschlag, den Informationsgehalt eines Dokumentes von seiner äußeren Form zu trennen. Ebenfalls Ende der sechziger Jahre veröffentlichte Stanley Rice, ein New Yorker Buch-Designer, seine Idee der "editorial structure tags", woraus später das "generic markup" entstand. Der Begriff des "markup" stammt aus dem Verlagswesen, aus einer Zeit als Begriffe wie Desktop Publishing noch unbekannt waren. Nach der inhaltlichen überprüfung und Korrektur eines Manuskriptes folgte die Bearbeitung durch den Layouter, der die Entscheidungen über Seitenformat, Zeichensätze und weitere typographische Festlegungen traf. Diese wurden in Form von handschriftlichen Markierungen und Anweisungen in das Manuskript eingefügt und anschließend im Druck berücksichtigt.
Eine genaue Umsetzung dieser Vorgehensweise spiegelte sich dann auch in elektronischen Dokumenten wider. Texte enthielten Steuerzeichen oder Makros, die Anweisungen für die Formatierung enthielten. Als später der Trend begann, Schreibmaschinen durch Computer zu ersetzen, lebte dieses Konzept fort. Noch heute arbeiten die gängigen Textverarbeitungen nach diesem Prinzip. Zwar stellen die modernen WYSIWYG-Programme die Steuerzeichen nicht mehr auf dem Bildschirm dar, sondern können dank graphischer Oberflächen Attribute wie Fettdruck, Unterstreichungen und verschiedene Zeichensätze unmittelbar anzeigen, die Fixierung auf das Layout des Dokumentes herrscht jedoch noch immer vor.
Generic Coding
Um so erstaunlicher, daß die Idee des generic coding schon so alt ist. Wodurch zeichnet sich nun dieses Konzept aus? Im Gegensatz zum format-orientierten Ansatz geht es beim generic coding darum, die Struktur und logischen Elemente eines Dokumentes zu kennzeichnen. Diese Art der Information geht bei der üblichen Vorgehensweise verloren. Setzt ein Verfasser eine überschrift in einer größeren Schriftart, so kann ein Leser diesen Text durchaus als überschrift erkennen, der Computer "weiß" jedoch nichts davon. Das Dokument enthält in diesem Fall nur die Information, wie ein Text darzustellen ist, aber nicht, um was für einen Text es sich handelt. Genau hier setzt das generic coding an. Markierungen sagen etwas über die Art (generic, Englisch: artmäßig) der markierten Stelle aus. Die "Art" bezeichnet hier zum Beispiel eine überschrift, einen hervorgehobenen Text, eine Fußnote, ein Zitat und so weiter. Die Vorteile liegen auf der Hand. Die Struktur des Dokumentes geht bei der Speicherung nicht verloren. Die Zuordnung eines bestimmten Aussehens zu einer bestimmten Klasse von Textstellen ist global möglich. Dadurch ist gewährleistet, daß alle gleichartigen Texte, zum Beispiel überschriften, stets gleich aussehen.
Das waren die ursprünglichen Ideen von Tunnicliffe und Rice. Die Bedeutung dieser Ideen erkannte Norman Scharpf, Direktor der CGA. Er gründete ein Komitee, dessen Entwicklung des "GenCode"-Konzeptes später Bedeutung für SGML erlangte.
Goldfarb, Mosher und Lorie (GML)
Ebenfalls auf den Ideen von Tunnicliffe und Rice basierend, entwickelten Charles Goldfarb, Edward Mosher und Raymond Lorie im Jahre 1969 bei IBM die Generalized Markup Language (GML). GML enthielt erstmals das Konzept eines formal definierten Dokumenttyps mit einer verschachtelten Struktur. Nach der Fertigstellung von GML formulierte Goldfarb weitere Konzepte, die zwar nicht in GML, aber später in SGML Einzug hielten.
Die Entwicklung zu einem Standard begann 1978, als das American National Standard Institute (ANSI) ein Komitee gründete, dessen Ziel die Entwicklung einer standardisierten Textbeschreibungssprache auf GML-Basis war. Goldfarb war Mitglied dieser Gruppe, die auch vom CGA-GenCode-Komitee Unterstützung erhielt. Nach mehreren Normentwürfen fand 1984 eine Neuorganisation des Projektes unter Leitung des ANSI und inzwischen auch der International Organization for Standardization (ISO) statt. Die zuständige Arbeitsgruppe der ISO unter Leitung von James Mason vom Oak Ridge National Laboratory rief regelmäßige Treffen ins Leben. Parallel dazu arbeitete das ANSI-Komitee, geleitet von William Davis (SGML Associates), immer noch unterstützt vom GenCode-Komitee, dessen Leiter Sharon Adler von IBM war. Die Abstimmung zwischen ISO und ANSI lag in den Händen von Charles Goldfarb.
Ein letzter Entwurf für den internationalen Standard wurde im Oktober 1985 präsentiert. Nach einem weiteren Jahr, in dem man Anregungen und Kommentare einarbeitete, gipfelte die Arbeit 1986 in der Veröffentlichung der Standard Generalized Markup Language als ISO-Standard 8879.
Dokumente mit Struktur
Bereits im Zusammenhang mit GML ist der Begriff des Dokumenttyps gefallen. Was ist das überhaupt?
Wenn man sich verschiedene Texte hinsichtlich ihres Aufbaus und ihrer Struktur ansieht, stellt man gewisse Gemeinsamkeiten und Unterschiede fest. Je nachdem wie groß diese Differenzen sind, zählt man verschiedene Dokumente zum selben oder zu unterschiedlichen Typen.
Bei dem Versuch den Dokumenttyp "Buch" näher zu charakterisieren, fällt die Gliederung in Kapitel, Abschnitte, Unterabschnitte und letztlich Absätze auf. Die Anzahl und die Tiefe der Gliederungen variiert von Buch zu Buch. Trotz dieser Unterschiede erscheint es sinnvoll, zwei Bücher als gleichartig einzuordnen, auch wenn die Anzahl der Kapitel voneinander abweicht.
Eine formale Typisierung von Dokumenten muß also die Gemeinsamkeiten festlegen, zugleich aber genügend Flexibilität für den konkreten Fall lassen.
Document Type Definition
In SGML erfolgt die Charakterisierung eines Dokumenttyps in der "Document Type Definition" (DTD). Die theoretische Grundlage hierfür bilden die "regulären Grammatiken" (siehe Kasten "Formale Sprachen").
Die DTD legt fest, welche logischen Elementen ein Text enthalten darf, welche Elemente unbedingt vorhanden sein müssen und in welcher Reihenfolge die Elemente erscheinen dürfen. Um das Beispiel "Buch" weiter zu verfolgen, ein Buch muß in jedem Fall einen Titel haben, der auch zwingend am Anfang erscheinen muß. Ein Index hingegen ist optional. Eine Verknüpfung mit einem bestimmten Layout ist in der DTD nicht enthalten. (siehe auch Kasten "Beispiel")
Beispielhafte Dokumente
Ein konkreter Text trägt in der SGML-Terminologie die Bezeichnung "Instanz". Dieser Begriff ist von dem englischen Wort "instance" (Beispiel) abgeleitet.
In der Instanz erfolgt die Identifikation des Dokumenttyps normalerweise durch eine Referenz auf die DTD. Die Referenzierung findet dabei in Form eines "External Entity" statt. External Entities sind Teile eines Dokumentes, die nicht in der Hauptdatei gespeichert sind. Die Hauptdatei darf auch ausschließlich aus Verweisen auf andere Dateien bestehen, etwa die DTD, die Instanz, Subdokumente und so weiter. Das Zusammenfügen aller Komponenten übernimmt ein Teil des verarbeitenden Systems, der sogenannte "Entity Manager".
Multimediafähig? Ja, aber ...
Für externe Dokumentteile kommen nicht nur textuell darstellbare Daten in Frage, sondern insbesondere solche, die nicht in SGML-Form gespeichert sind.
Grafiken, Animationen und Audiodaten liegen außerhalb des SGML-Standards. SGML bietet über den Entity-Mechanismus lediglich die Möglichkeit, einen Verweis auf die externen Dateien in die Instanz einzufügen. Die Art der Darstellung, auf dem Bildschirm oder auf dem Papier, bleibt völlig dem entsprechenden Anwendungsprogramm überlassen. Da diese Daten aber Teil des Dokumentes sind, ist SGML in diesem Sinne multimediafähig.
Literatur
[1] Charles F. Goldfarb; The SGML Handbook; Oxford University Press, 1990
[2] ISO/IEC DIS 10179.2 Information technology - Text and office systems - Document Style Semantics and Specification Language (DSSSL) ftp://ftp.jclark.com/pub/dsssl/
[3] J.E. Hopcroft, J.D. Ullman; Einführung in die Automatentheorie, Formale Sprachen und Komplexitiätstheorie; Addison-Wesley, 1990
[4] The LaTeX Companion; Goosens, Mittelbach, Samarin; Addison-Wesley, 1993
Formale Sprachen und der Zusammenhang zu SGML
Die Theorie der formalen Sprachen entstand aus dem Verlangen, natürliche Sprachen formal beschreiben zu wollen. Der Ursprung geht auf den US-amerikanischen Linguisten Noam Chomsky zurück. Er entwickelte verschiedene Modelle für Grammatiken, die in der "Chomsky-Hierarchie" zusammengefasst sind und in der Informatik eine sehr große Bedeutung erlangt haben.
Programmiersprachen lassen sich zum Beispiel durch die sogenannten kontextfreien Grammatiken erfassen. Leicht abgewandelte Chomsky-Grammatiken bilden die Grundlage der L-Systeme, mit denen der Biologe Aristid Lindenmayer und der Computerwissenschafter Przemyslaw Prusinkiewicz den Aufbau von Pflanzen modelliert haben.
Im Zusammenhang mit SGML sind formale Sprachen von Interesse, da bereits die einfachste Form der Chomsky-Grammatiken, die regulären Grammatiken, für die Beschreibung einer DTD ausreichen. Die folgenden Beispiele sollen das Prinzip erläutern. Auf den Unterschied zwischen den verschiedenen Typen kommt es hier nicht an.
Bei dem Begriff "Grammatik" denkt jeder zunächst an seine Muttersprache, unter Umständen mit mehr oder weniger guten Erinnerungen an die eigene Schulzeit. Das erste Beispiel stammt aus diesem Bereich:
Wie ist ein Satz aufgebaut? In einer einfachen Form besteht ein Satz aus einem Subjekt, einem Prädikat und einem Objekt. Schematisch dargestellt:
<Satz> --> <Subjekt> <Prädikat> <Objekt>
Aber nicht jeder <Satz> besteht aus diesen drei Elementen. Das <Objekt> ist optional. Dies drückt sich durch ein angehängtes Fragezeichen aus:
<Satz> --> <Subjekt> <Prädikat> <Objekt>?
Das <Objekt> läßt sich auch noch feiner charakterisieren. Hier kommt eine zweite Regel ins Spiel:
<Satz> --> <Subjekt> <Prädikat> <Objekt>? <Objekt> --> <Akkusativobjekt> | <Dativobjekt> | <Genitivobjekt>
Der senkrechte Strich zwischen den Elementen bedeutet, daß ein <Objekt> nicht eine Verkettung der drei Elemente auf der rechten Seite ist, sondern durch eine Entweder-oder-Auswahl durch genau eines der rechtsstehenden Elemente zu ersetzen ist.
Alle Elemente, die man nicht weiter untergliedern kann, führen zu Terminalen. In diesem Beispiel sind Terminale einfach die Wörter des entsprechenden Typs:
<Subjekt> --> Substantiv | Pronomen <Prädikat> --> Verb <Akkusativobjekt> --> Substantiv <Dativobjekt> --> Substantiv <Genitivobjekt> --> Substantiv
Eine Grammatik besteht aus allen Symbolen (Hilfsymbole und Terminalsymbole) und aus allen Produktionsregeln.
Mit den oben aufgestellten Regeln, lassen sich verschiedene Sätze konstruieren. Die Frage, ob ein Satz grammatikalisch korrekt ist, kann man dadurch beantworten, daß man versucht, den konkreten Satz durch die obigen Regeln zu konstruieren. Gelingt dies, so ist der Satz im Sinne der Grammatik korrekt. Beispiel: Den Satz "Der Virus löschte die Daten" erzeugen folgende Ableitungen:
<Satz> --> <Subjekt> <Prädikat> <Objekt> <Subjekt> --> Der Virus <Prädikat> --> löschte <Objekt> --> <Akkusativobjekt> <Akkusativobjekt> --> die Daten
Eine übersichtlichere Darstellung ist in Form eines Baumes möglich.
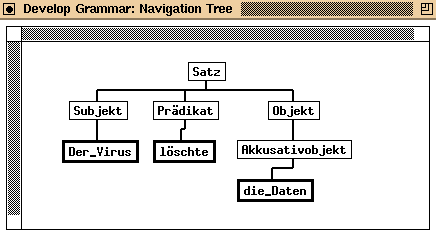
überträgt man das obige Beispiel auf SGML, so entstehen folgende Analogien. Die Grammatik entspricht einer SGML-DTD. Der konkrete Satz entspricht einer Dokumentinstanz, einem konkreten Dokument. Die überprüfung auf Korrektheit übernimmt ein SGML-Parser. Dieser testet, ob das Dokument zu den Regeln in der DTD passt.
Wie SGML zu der Bezeichnung "Metasprache" kommt, sollte durch die bisherigen Ausführungen deutlich geworden sein. DTDs sind vergleichbar mit Grammatiken oder Sprachen. SGML liefert den Formalismus, um verschiedene DTDs (und damit Sprachen) zu definieren.
Zur Veranschaulichung nun noch ein Beispiel. Als Dokumenttyp soll hier ein iX-Artikel dienen. Wie ist ein solcher Artikel aufgebaut, wie lautet die Grammatik? Dieser Frage kann man sich schrittweise nähern. Der erste Schritt unterteilt den Artikel in drei Komponenten.
<ixart> --> <kopf> <rumpf> <fuss>
Der <kopf> besteht aus vier Elementen, die selbst nicht weiter zu untergliedern sind.
<kopf> --> <thema> <titel> <autor> <prolog> <thema> --> TEXT <titel> --> TEXT <autor> --> TEXT <prolog> --> TEXT
Bis hierher war die Analyse recht einfach. Der <rumpf> jedoch ist etwas komplexer. Er besteht aus einzelnen Absätzen mit Text, durchsetzt mit Zwischenüberschriften und abgesetzten Kästen, die Texte, Grafiken oder Tabellen enthalten. Eine mögliche Spezifikation ist die folgende. (Das Sternsymbol kennzeichnet ein Element, das gar nicht oder mehrfach auftreten darf. Zur Vereinfachung erscheint hier der Inhalt eines Kastens als reiner Text.)
<rumpf> --> <absatz> <rumpfelement>* <rumpfelement> --> <kasten>* <absatzelement>* <absatzelement> --> <zwueberschrift>? <absatz> <kasten> --> TEXT <zwueberschrift>--> TEXT <absatz> --> TEXT
Abschließend noch die Umsetzung der (unvollständigen) Regeln in SGML-Notation. Die Grammatik läßt sich fast unmittelbar in eine DTD überführen.
<!ELEMENT ixart - - (kopf, rumpf, fuss)> <!ELEMENT kopf - - (utitel, titel, autor, intro)> <!ELEMENT thema - - (%TEXT;)> <!ELEMENT titel - - (%TEXT;)> <!ELEMENT autor - - (%TEXT;)> <!ELEMENT prolog - - (%TEXT;)> <!ELEMENT rumpf - - (absatz, (%r-elem;)*)> <!ENTITY % r-elem "(kasten*, (%a-elem;)*)" > <!ENTITY % a-elem "(zwueber?, absatz)" > <!ELEMENT absatz - - (%TEXT;)> <!ELEMENT kasten - - (%TEXT;)> <!ELEMENT zwueber - - (%TEXT;)> <!ENTITY % TEXT "#PCDATA" >
Praktische Probleme
Für Leser mit einigem Fachwissen soll der Zusammenhang von SGML mit der Automatentheorie angesprochen werden. Reine Anwender können diesen Teil ignorieren.
Die zuvor so problemlos dargestellte überprüfung der Instanz ist in der Tat nicht ganz so leicht. Es geht hier um die Akzeptierung oder Zurückweisung eines regulären Ausdrucks. Dies kann mit Hilfe eines äquivalenten "Deterministischen Endlichen Automaten" (DEA) geschehen. Ein DEA entspricht einem Algorithmus der leicht von einem Computer ausführbar ist. Die Konstruktion eines solchen DEA führt über ein weiteres Modell, den "Nichtdeterministischen Endlichen Automaten" (NEA). Die überführung eines regulären Ausdrucks in einen NEA ist unmittelbar möglich. Schwierig wird es bei der Umwandlung des NEA in den DEA. Die Laufzeit der entsprechenden Algorithmen kann sehr hoch sein, man spricht hier von nicht-polynomieller Laufzeit.
Um diese Probleme erst gar nicht zuzulassen, schafft SGML die Notwendigkeit der Konstruktion eines DEA ab. Dies geschieht durch Einschränkungen der regulären Ausdrücke in der Art, daß ein Programm den entsprechenden NEA deterministisch durchlaufen kann.
Weitere Ausführungen würden hier zu weit führen. Interessierte Leser finden eine genaue Darstellung der Zusammenhänge mit der Automatentheorie im SGML Handbook [1].
Make-Up für das Markup
Die Trennung von Inhalt und Layout und die damit verbundenen Vorteile sind ja ganz schön, aber früher oder später möchte man doch mal ein formatiertes Dokument sehen.
Prinzipiell kommt für die Aufbereitung natürlich jeder Formatierer in Frage, zum Beispiel TeX oder troff. Dazu muß ein Konverter das SGML-Dokument in eine entsprechende syntaktische Form bringen, die das jeweilige Formatierungsprogramm versteht. Diese Lösung ist aber völlig von SGML getrennt.
Im folgenden soll es darum gehen, welche Möglichkeiten im Rahmen von SGML zur Verfügung stehen, um Einfluß auf das Aussehen des Dokumentes zu nehmen. Insbesondere die Vor- und Nachteile sind hier von Interesse.
Processing-Instructions
Der rudimentärste Weg, Anweisungen für die Verarbeitung eines Dokumentes anzugeben, sind die "Processing-Instructions". Dabei handelt es sich um eine spezielle Form von Markup, das eine bestimmte Syntax besitzt. Eine Processing-Instruction hat die Form <? ... >, zum Beispiel: <?Font=Times-Roman>. Was zwischen diesen Markierungen steht, ist im SGML-Standard nicht festgelegt. Das heißt, daß die Wirkung voll und ganz von dem verarbeitenden System abhängt. Als Vorteil ist anzuführen, daß diese Anweisungen, aufgrund ihrer Syntax, leicht von dem generic markup unterscheidbar sind. Ein Programm, das die Markierungen nicht versteht, kann sie ignorieren und den übrigen Teil des Dokumentes dennoch verarbeiten.
Ohne Frage sind die Processing-Instructions aber kein eleganter Weg, um das Layout zu spezifizieren. Sie stehen in krassem Gegensatz zur SGML-Philosophie, die sich nicht zuletzt durch Hardware- und Softwareunabhängigkeit auszeichnet.
Steuerung der Verarbeitung durch Attribute
Ein zweiter Weg der Verarbeitungssteuerung beginnt bereits in der DTD.
Jedes Element kann eine Reihe von Attributen besitzen, mit jeweils einem eigenen Wertebereich.
Damit sind zum Beispiel symbolische Querweise realisierbar: Angenommen, die Tags <figure id="bild1">...</figure> kennzeichnen ein Bild. Eine Bezugnahme kann dann etwa die Form siehe Bild <figref idref="bild1"> haben. Die verwendeten Attribute heißen hier also "id" bzw. "idref" und beide besitzen den Wert "bild1".
Auf diesselbe Art ist die Beeinflußung des Layouts denkbar. Der Name des Attributes bezeichnet, was sich bei der Formatierung ändern soll. Die möglichen Werte legen die änderung des Aussehens fest. Auch hier soll ein Beispiel weiterhelfen:
Attribute sollen die Erscheinungsweise eines Absatzes steuern. übliche Optionen sind "linksbündig", "rechtsbündig" und "Blocksatz". Ein zweites Attribut steuert die Einrückung des linken und rechten Randes. In der Praxis kann das so aussehen:
<absatz ausrichtung="links"> Ein linksbündig formatierter Absatz, ohne Randeinrückung. </absatz> ... <absatz ausrichtung="blocksatz" linkerRand="5"> Ein weiterer Absatz. Diesmal im Blocksatz und mit einem linken Rand, der um 5 Einheiten eingerückt ist. </absatz>
Diese Beispiel zeigt, daß auch dieser Weg der Layout-Spezifikation nicht unabhängig von der verarbeitenden Software ist. Ein Formatierer muß alle Fähigkeiten bieten, die die Attributwerte dem Autor zur Auswahl stellen.
Die Wertemenge der Attribute ist durch die DTD festgelegt. Im Gegensatz zu den Processing-Instructions kann hier nicht jeder Verfasser eigene Wege gehen. Ein Nachteil ist, daß die besondere Semantik der Attribute nicht an der Syntax zu erkennen ist. Diese Form der Layoutspezifikation ist nicht vom generic markup unterscheidbar. Auch das zeigen die obigen Beispiele. Sowohl die Querverweise, die kein bestimmtes Aussehen implizieren, als auch die Einrücktiefe eines Absatzes sind durch Attribute realisiert. Zu Beachten ist auch, daß eine spätere änderung der Attribute in der DTD sehr problematisch sein kann. Bereits beim Entwurf der DTD sollten alle Attribute und Werte festliegen.
Auf die linke Tour: das Link-Feature
Ein gemeinsames Problem von Processing-Instructions und verarbeitungs-orientierten Attributen ist, daß Layout und Inhalt des Dokumentes nicht getrennt sind. Dieses Problem wird durch die "link process definitions" (LPD) entschärft.
Die Möglichkeiten der LPDs sind vielfältig und dementsprechend auch etwas komplizierter. Aus diesem Grund soll hier nur eine kurze Skizzierung des Prinzips stattfinden.
Die Grundlage bilden die schon bekannten Attribute, die in diesem Zusammenhang auch die Bezeichnung "Link-Attribute" tragen.
Die Definition der Attribute erfolgt nicht mehr in der DTD, sondern in der link process definition. Damit ist schon ein wichtiger Schritt erreicht, nämlich die Trennung der Strukturdefinition (in der DTD) von der Definition der verarbeitungs-orientierten Attribute (in der LPD).
Der zweite Schritt besteht darin, die Dokumentinstanz von den Attributen zu befreien. Wie die obigen Beispiele zeigen, erscheinen die Attribute in den Start-Tags. Das Link-Feature verlagert die Zuordnung von einem Attributwert zu einem Start-Tag in die LPD.
Konkret heißt das, daß in der LPD steht, welcher Start-Tag automatisch mit welchem Attribut versehen wird. Hierzu ein Beispiel. Hervorgehobener Text soll kursiv erscheinen. In der Instanz werde der Text etwa durch <em>...</em> markiert. Während der Verarbeitung erhält die markierte Stelle das Attribut, das in der LPD für hervorgehobenen Text angegeben ist, etwa <em fontshape=italic>...</em>.
Die Steuerung der Zuordnung kann kontextsensitiv ablaufen. Bei geschachteltem hervorgehobenen Text macht es wenig Sinn, innerhalb von kursivem Text nochmal kursiven Text zu setzen. In diesem Fall wäre eine Zurückschaltung auf normale Schriftart sinnvoll. Aus <em>...<em>...</em>...</em> könnte bei entsprechender Definition in der LPD
<em fontshape=italic>
...
<em fontshape=normal>
...
</em>
...
</em>
werden.
Wem die Möglichkeiten der LPDs nicht ausreichen, der kann sogenannte Style-Sheets als externe Entities einbinden. Wie solche Style-Sheets aussehen, ist im SGML-Standard nicht definiert. Sie bilden damit eine Schnittstelle für beliebige Formatierungsanweisungen, die zwar systemabhängig, aber wenigstens sauber vom Inhalt getrennt sind.
Zum Abschluß der link process definitions sei erwähnt, daß ein Dokument mehrere LPDs enthalten darf. Sinnvoll ist dies zum Beispiel, um für verschiedene Ausgabemedien die entsprechenden Attributwerte zu definieren. Beispielsweise sind bei der Bildschirmausgabe die Definitionen aus der Bildschirm-LPD aktiv, der Druckertreiber benutzt die Werte der Druck-LPD.
Fortsetzung folgt: DSSSL
Der letzte Punkt ist - wenn man es genau nimmt - hier etwas deplaciert, da er im engeren Sinne nichts mit SGML zu tun hat. Die Rede ist von der sogenannten "Document Style Semantics and Specification Language", abgekürzt DSSSL (sprich "Dissel"). Hinter diesem unhandlichen Begriff versteckt sich die konsequente Fortsetzung von SGML.
SGML erlaubt die formale Beschreibung einer Dokumentstruktur und logischer Textelemente und zwar in einer systemunabhängigen Weise. Sobald man auf die Frage der Formatierung oder allgemein der Verarbeitung eines Dokumentes stößt, erreicht man früher oder später die Grenze, an dem eine gewisse Systemabhängigkeit eintritt. Dies ist letzlich nicht zu vermeiden, da man natürlich irgendwann sein Dokument ansehen, ausdrucken oder abspielen möchte.
DSSSL verschiebt diese Grenze noch einen Schritt weiter nach hinten. Die Verarbeitung eines Dokumentes läßt sich mit Hilfe von DSSSL frei von einer bestimmten Software oder Hardware beschreiben.
Dieser Vorgang unterteilt sich in zwei Schritte. Der erste Durchgang verändert die Struktur des Ausgangsdokumentes. Daß eine SGML-Instanz als Baum repräsentiert werden kann, ist bereits bekannt. Aus diesem Grund trägt der erste Schritt die Bezeichnung "SGML Tree Transformation Process" (STTP).
Ob und wozu dieser Schritt nötig ist, hängt selbstverständlich vom konkreten Zweck ab. Zur Veranschaulichung zwei Beispiele. Angenommen, in einem Buch sollen die Fußnoten nicht am unteren Rand der Seite erscheinen, sondern gesammelt am Ende des Abschnittes. Der STTP kann dazu an der Stelle des Auftretens der Fußnote eine Referenz setzen und den Text der Fußnote an das Ende des Abschnitts verschieben. Dieser Fall zeigt das Einfügen (die Referenz) und das Verschieben von Daten (der Fußnotentext). Auch das Entfernen von Daten kann sinnvoll sein. Für die Aufnahme von Adressen aus Briefen in eine Datenbank löscht der STTP sämtlichen anderen Inhalt und läßt nur die Adressen übrig. Die anschließende Aufnahme in den Datenbestand ist dann leicht durchzuführen.
Diese Beispiele zeigen, daß das Ausgabedokument des Transformationsprozesses unter Umständen vollkommen von der ursprünglichen DTD abweicht.
Nach der Transformation folgt die Formatierung, in DSSSL mit der Bezeichnung "SGML Tree Formatting Process" (STFP) versehen.
DSSSL ist, wie auch SGML, sehr allgemein formuliert. Dies muß natürlich so sein, um allen möglichen - auch zukünftigen - Anforderungen zu genügen. Wirklichen Nutzen aus SGML und DSSSL kann der Endanwender erst dann ziehen, wenn die entsprechenden Programme verfügbar sind. Während die Erstellung einer SGML-Instanz noch relativ einfach ist, bleibt DSSSL den Profis vorbehalten. Als Spezifikationssprache kommt eine Sprache zum Einsatz, die auf Scheme - einem Lisp-Dialekt - aufbaut.
Hier muß man warten, bis die nötige Entwicklungsarbeit geleistet ist. Aber das kann noch eine Weile dauern, denn DSSSL ist noch nicht als Standard verabschiedet. Zur Zeit existiert lediglich ein Entwurf, ein "Draft International Standard" (DIS).
Anwendungen für SGML
Ein typisches Anwendungsgebiet für SGML findet sich im Verlagswesen. Ein Problem ist hier das Format, in dem eingehende Manuskripte vorliegen. Wenn jeder Autor sein bevorzugtes Programm benutzt, stellt sich die Frage, nach der Konvertierung in das verlagsinterne Format. Eine Lösung ist, sich auf den kleinsten gemeinsamen Nenner, das ASCII-Format, zu einigen. Das funktioniert zwar, bedeutet aber zusätzliche Arbeit, da nur eine manuelle Aufbereitung der Texte möglich ist. Gibt der Verlag jedoch eine SGML-DTD vor, an die sich die Autoren halten, so lassen sich eingehende Dokumente unmittelbar verarbeiten.
Das Interesse im Verlagswesen zeigte sich sehr früh. Die Association of American Publishers (AAP) arbeitete bereits 1983, noch im Entwurfsstadium, an einer SGML-Anwendung.
Andere Gebiete in denen SGML erfolgreich ist, haben mit dem eben genannten Beispiel gemein, daß eine übergeordnete Instanz den jeweiligen Verfassern vorschreibt, daß die Dokumente in SGML abzuliefern sind. Neben der AAP war das US-amerikanische Verteidigungsministerium einer der ersten großen Benutzer. Die Vereinigung der Flugzeughersteller und Luftfahrtgesellschaften (ATA) verlangt die Dokumentation für Flugzeuge gemäß eigener DTDs.
Aber nicht nur für den Informationsaustausch zwischen verschiedenen Firmen oder Institutionen ist SGML sinnvoll. Auch innerhalb einer Firma, im Workflow-Management, ist ein standardisiertes Format von Nutzen. Die Weitergabe eines elektronischen Dokumentes von einer Abteilung an eine oder mehrere andere Abteilungen führt oft Schwierigkeiten. Unbedingte Voraussetzung ist, daß der Empfänger das (proprietäre) Dateiformat lesen kann. Bei Einsatz der gleichen Software ist das kein Problem. Wer aber garantiert, daß der Absender auch die benötigten Informationen mitgeschickt hat? Unter Umständen verwendet der Empfänger nur einen Teil des Textes, muß sich dazu aber den entsprechenden Abschnitt selbst heraussuchen. Mit SGML passiert dies nicht. Eingehende Dokumente überprüft ein SGML-Parser auf (syntaktische) Korrektheit und Vollständigkeit. Die relevanten Informationen extrahiert die Software vollautomatisch und bereitet sie für die Weiterverarbeitung auf.
Für einen derart reibungslosen Ablauf ist natürlich ein hoher Initialaufwand in Form von Software (Anschaffung oder Entwicklung) und Personalschulung nötig.
Beispiel
Wie eine DTD und ein Instanz aussehen, soll das folgende Beispiel zeigen.
SGML basiert auf dem 7-Bit-ASCII-Zeichensatz. Grundsätzlich ist es also möglich jeden beliebigen Editor zu benutzen.
Eine weitere Konsequenz davon ist, daß das Markup durch eine festgelegte Syntax vom Inhalt unterscheidbar sein muß. Die ISO-Norm definiert die "Reference Concrete Syntax". Abweichungen davon kann der Benutzer in der "Variant Concrete Syntax" definieren. Dies findet im folgenden aber keine Verwendung.
Das Markup besteht im wesentlichen aus den "Tags" (engl.: Schildchen, Etikett). Tags beginnen und enden mit einer öffnenden bzw. schließenden spitzen Klammer. Man unterscheidet "descriptive markup", das in der Instanz die Textelemente kennzeichnet, "markup declarations", die in der DTD die Struktur des Dokumenttyps festlegen und "processings instructions", die Informationen für die Verarbeitung enthalten.
Markup declarations und processings instructions sind durch ein Ausrufungszeichen bzw. durch ein Fragezeichen gekennzeichnet. Die Elemente in der Instanz sind in ein Start-Tag und ein End-Tag eingebettet. Das End-Tag kennzeichnet ein Schrägstrich.
Für das folgende Beispiel soll der - sehr einfache - Dokumenttyp "Notiz" dienen. Eine Notiz soll einen Titel haben, aus mindestens einem Absatz bestehen und im Text sollen wichtige Stellen markierbar sein:
<!-- Element Min Inhalt --> <!ELEMENT notiz - - (titel, absatz+) > <!ELEMENT titel - - (#PCDATA) > <!ELEMENT absatz - - (#PCDATA | wichtig)* > <!ELEMENT wichtig - - (#PCDATA) >
Das reservierte Wort #PCDATA (parsed character data) kann hier als reiner Text verstanden werden.
Angenommen diese DTD ist als Datei /usr/home/sm/dtd/notiz.dtd abgespeichert. Dann kann eine Instanz dieses Dokumenttyps so aussehen:
<!DOCTYPE notiz SYSTEM "/usr/home/sm/dtd/notiz.dtd" [
]>
<notiz>
<titel>Termine</titel>
<absatz>
Dienstag, 9 Uhr:
<wichtig>Zahnarzttermin</wichtig>
</absatz>
<absatz>
...
</absatz>
</notiz>